


Fining an AI Builder case study can be challenging as I was always when I was presenting the model; how can we benefit from AI models in CRM implementations, or how will it solve business problems.
This post will discuss a real scenario of using AI Builder to solve a business case, as I will cover how I managed to build a POC to analyze the data and the model’s output was handled to make it worthwhile for end-users. This example will explain how the formating of the AI Builder text recognition was made to make the output readable as much as possible.
I will also discuss the business case of how AI Builder managed to extract the PDF content and how Power Automate managed to structure and formate the extracted text to increase the readability.
Read more about AI Builder Text recognition from the Microsoft Documentation site and explore how we discussed AI Builder before in D365Update.com.
Case Study background
I was always fascinated by AI and its use for business benefits alongside Dynamics 365 and business applications; that is why I have been reviewing and testing Microsoft AI builder since it came out. However, finding the use case is not easy!
Finally, I found a real business case for AI Builder, where the client had many PDFs stored in a legacy system. The PDFs contained a large amount of text in multiple pages and was viewed directly from the related record in the legacy system using a web PDF viewer.
The client wanted to retire the legacy system, migrate all the data to D365 and store all related documents in SharePoint.
The problem
After successfully migrating the data and the documents to Dynamics 365 and SharePoint, the client complained that the PDF’s text is no longer visible directly from the record as it was in the retired system.
Moreover, the client wanted to be able to perform advanced actions on the text, such as performing searches on the content of the PDFs across all records and making amends to the PDFs’ text.
In the future, the client will stop using PDFs to store data. Instead, they will store it directly on a rich field with a large character count on the record.
Possible solutions
One possible solution was to use a PDF viewer control within the record form, but we faced many issues such as,
- It is very difficult to browse multiple pages.
- Might be helpful for the old data, but not a valid solution for the new data generated after the migration.
- Most importantly, the content is not searchable and editable.
Therefore, we had to convert thousands of binary PDF files into editable text and store it in the CRM record.
The solution – AI Builder case study
At that time, I recognized that AI Builder text recognition is the best solution to solve the problem injunction with Power Automat to do the following.
- locate the PDF file in SharePoint from the related Dynamics 365 record.
- Process the content using the AI Builder
- Format the output
- Store the formated text in the destination record field.
We also needed to estimate how much it would cost to use AI Builder. Below, I will explain how we calculated the cost and how we acquired the AI builder. For more information about AI Builder Calculator.
Solution arcticture
The AI Builder case study solution required a Power Automate designed to be triggered manually. Then the flow will scan the Datavers for any records with attached PDF files.
To perform the text recognition on thousands of independent PDF files, we had to have a main Power Automate flow that runs manually to locate the PDF files and call on a child Power Automate flow that runs the AI Builder model and update Dynamics 365 record with the extracted data.
The child flow will be fired with the ID of the related Dataverse record to perform the needed actions on that specific record.
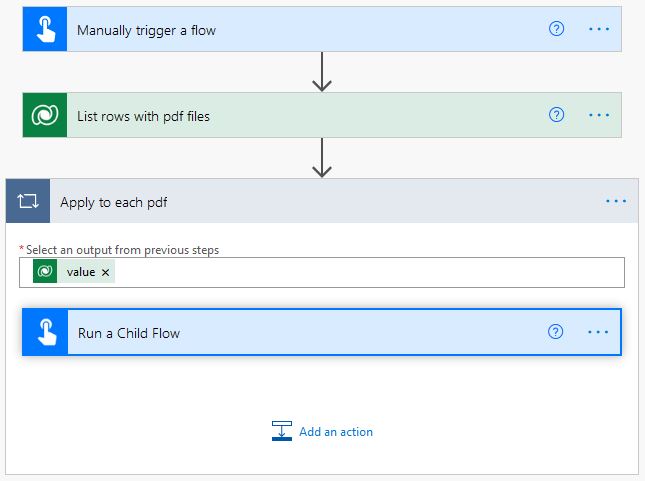
Anticipating errors
Although the destination record multi-line field was 50,000 characters, we had no idea how long the content of each of the PDFs was and if the 50,000 characters per field were enough for the extracted text. Therefore, we had to run the flow once before the execution only to count the number of characters of each PDF.
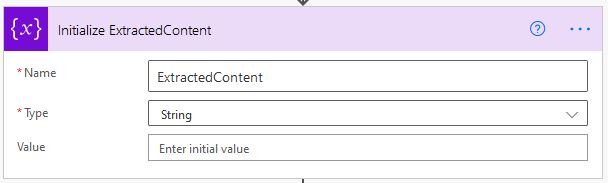
To count the character count, length expression was used to calculate the as below.
length(variables(‘ExtractedContent’))
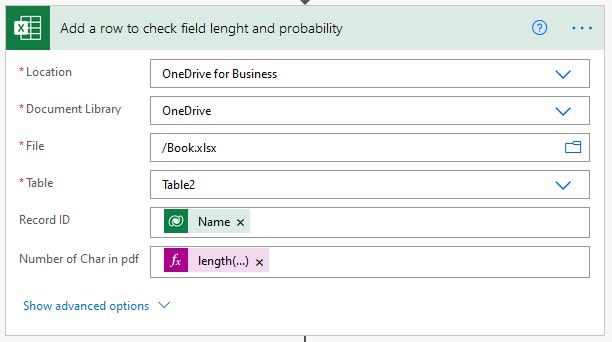
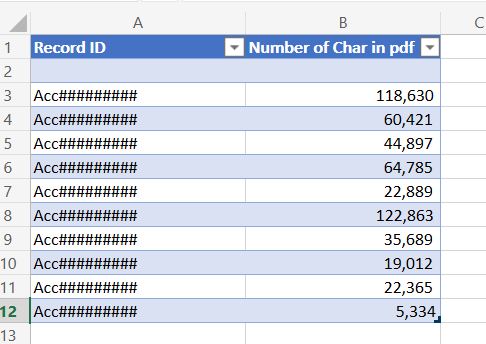
Using an excel sheet in the flow, we managed to store the results of all the extracts.
A sample result of the run, which took more than 24 hours, showed that the 50,000 characters field is not enough to host the extracted data.
Hence, we decided that the multi-line field needs to be extended to 150,000 characters.
The customization was made prior to the final run, which took another 24 hours to complete.
We spent an additional day before the final run using this method, but we avoided any potential errors.
Child Flow
AI Builder Module connctor
The child flow, that was hosted on the first day with the excel counter, got re-configured by the AI builder model and updated the Dataverse records with the extracted data.
AI Builder Results
The AI Builder case study shows that the text recognition module returned its results in an array of lines. Each of the lines requires to be appended in a flow variable.

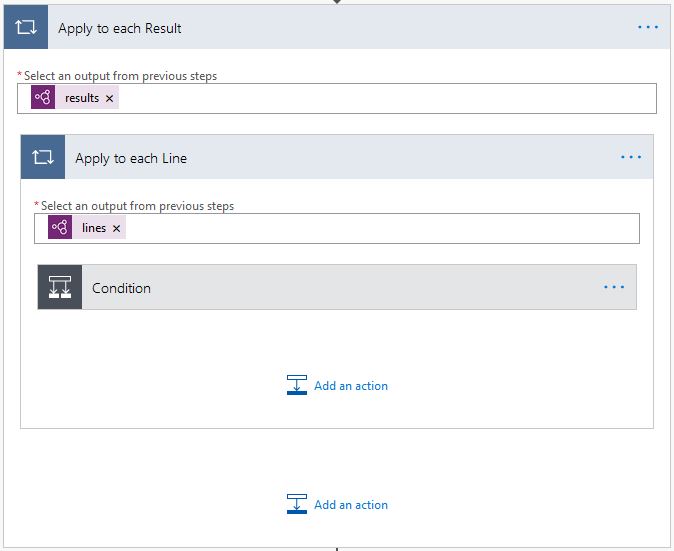
Formating the AI Builder output
The AI Builder, text recognition model, extract text line by line regardless of the position of this line to the paragraph that this line belongs to.
Once the text lines get appended, the variable text will have no line breaks, and each line ends merged into the following line start. This makes the text hard to read and not useful for the end-users. We expect that the extracted text not only have line breaks but also to be structured in headers and paragraphs.
To be able to correctly format the extracted text, we need to run a number of checks on the line ends. As the examples below.
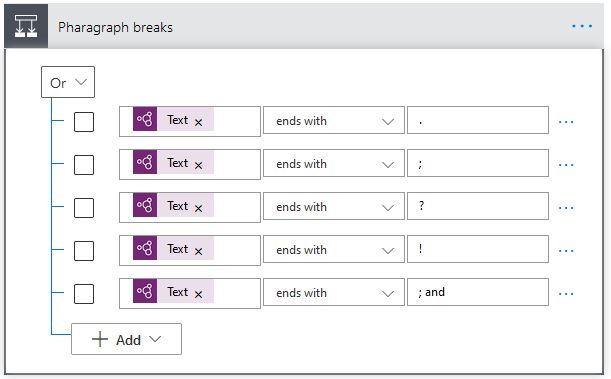
To realize the difference between the lines in the middle of paragraphs and the last line of the paragraph, we can check for the special characters such as the ones in the snapshots above (full stop, semicolumn, question mark or other)
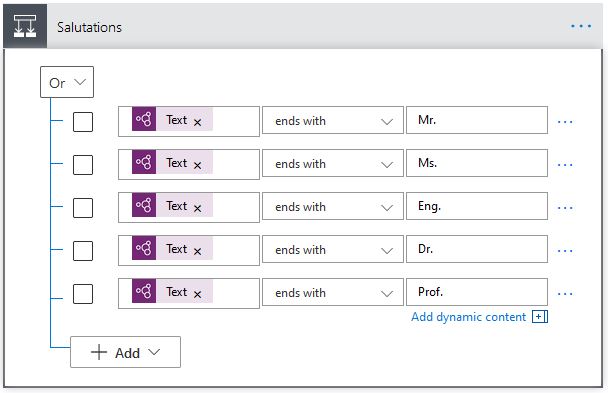
Check if the full stop is part of a salutation and not actually the paragraph end line, in this case, we need to avoid adding a paragraph end.
The two examples above are based on the data analyzed in the AI Builder case study and among many others that were created to analyze the line and include it in paragraph correctly.
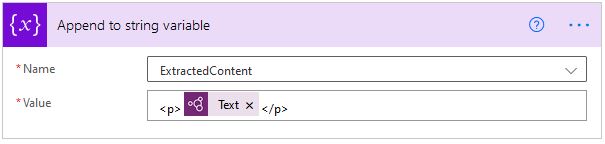
Append to the variable
In “Apply to each” control, then append to a string control can be configured to include rich format using HTML codes or using just line breaks.
BR and P tags can be used as the HTML codes or click one or two “Enter” or “Space”.
AI Builder case study estimation
AI Builder calculator estimates the potential cost based on the expected processed data. I estimated that one unit (50,000 images) is enough to perform the needed analysis for the text recognition model.

Trail for production use
The AI Builder case study requirement was needed to run for the historical data only, and the client will not be generating PDFs anymore. Thus, the AI Builder case study was necessary for one month only, and the administration work to obtain the AI Builder for only one month is not visible.
From the Microsoft AI Builder Licensing page and under the Trial Licensing section, as shown in the snapshot below.
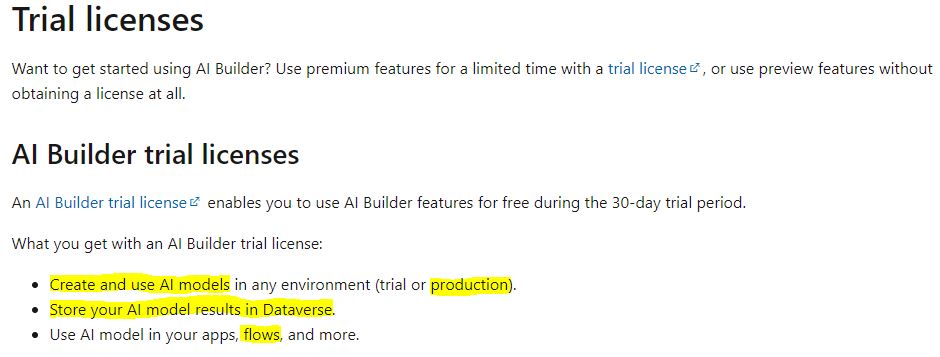
From the highlighted points in the snapshot above, I found the following
- can use the AI Builder trail in the production environment.
- Include the AI Builder in a flow, as we did above.
- Finally, store the extracted text in Dataverse as we did.